Fé Valvekens
7 years in IT Consulting and Business Intelligence in Paris, Geneva and Hong Kong, 10 years as an entrepreneur. Holds a Masters in Computer Science and completed the MIT Applied Data Science program.
Eager to develop and deploy innovative machine learning models to support clients in data driven decision-making across industries while supporting the causes that are dear to my heart: health, education and women empowerment.
View My LinkedIn Profile
Shinkansen Travel Experience Prediction
Problem Summary
The goal of the problem is to predict whether a passenger was satisfied or not considering his/her overall experience of traveling on the Shinkansen Bullet Train. The problem consists of 2 separate datasets: Travel data & Survey data. Travel data has information related to passengers and attributes related to the Shinkansen train, in which they traveled. The survey data is aggregated data of surveys indicating the post-service experience.
Models Explored
After performing Exploratory Data Analysis (EDA) on the two datasets, we imputed the missing values using the median and mode. We then prepared the data for modeling. We explored various classification models for prediction, and tuned them to improve the accuracy score, the chosen model evaluation criterion:
- Decision Tree
- Random Forest
- Logistic Regression
- Artificial Neural Network
- Convolutional Neural Network
- Support Vector Classifier (SVC)
- Light Gradient Boosting Machine (LightGBM)
We also tried feature engineering, and it slightly improved the accuracy.
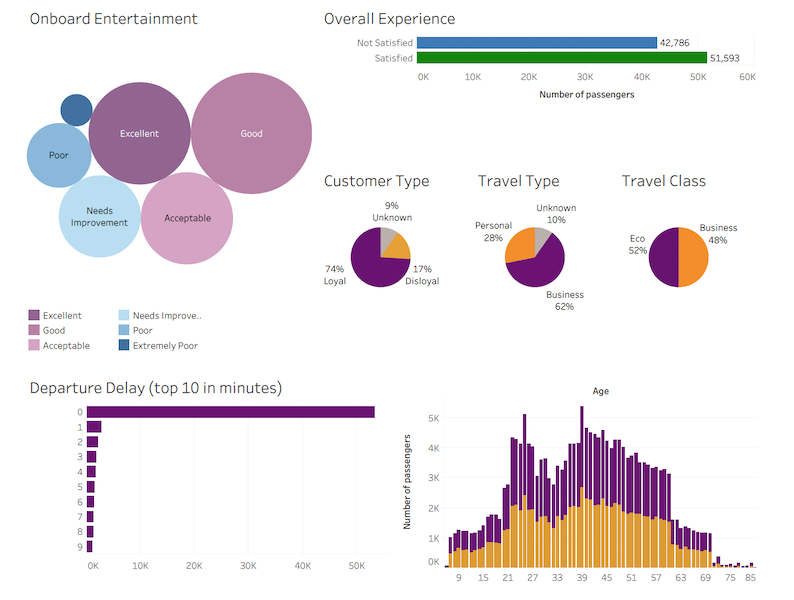
Data Visualisation
We created an interactive dashboard to visualize some data:
Tableau Dashboard
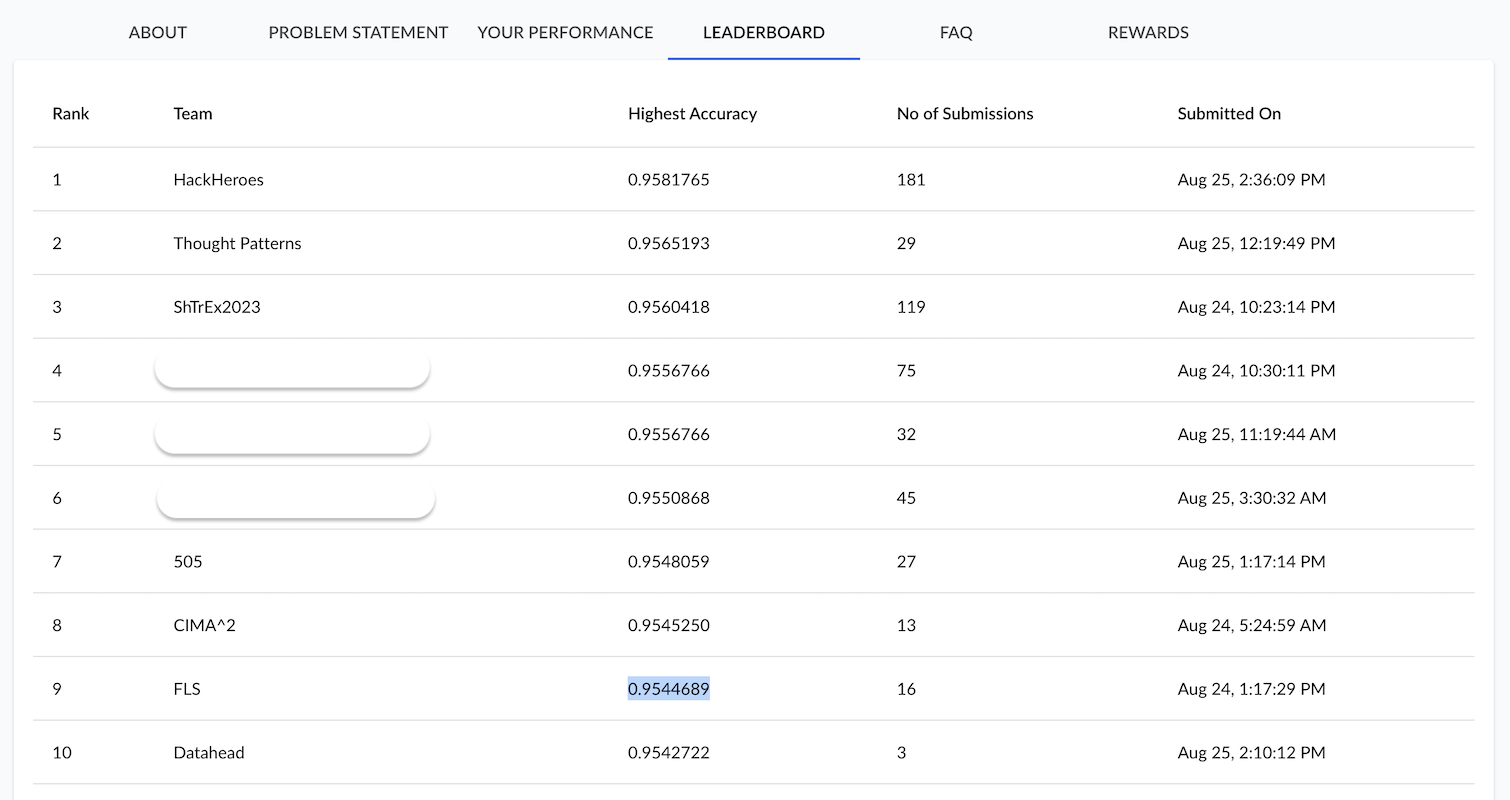
Leaderboard
Our best accuracy score, 95.44689%, was obtained with the LightGBM model. We made it to the top ten leadersboard!