Fé Valvekens
7 years in IT Consulting and Business Intelligence in Paris, Geneva and Hong Kong, 10 years as an entrepreneur. Holds a Masters in Computer Science and completed the MIT Applied Data Science program.
Eager to develop and deploy innovative machine learning models to support clients in data driven decision-making across industries while supporting the causes that are dear to my heart: health, education and women empowerment.
View My LinkedIn Profile
Face Emotion Detection
Executive Summary
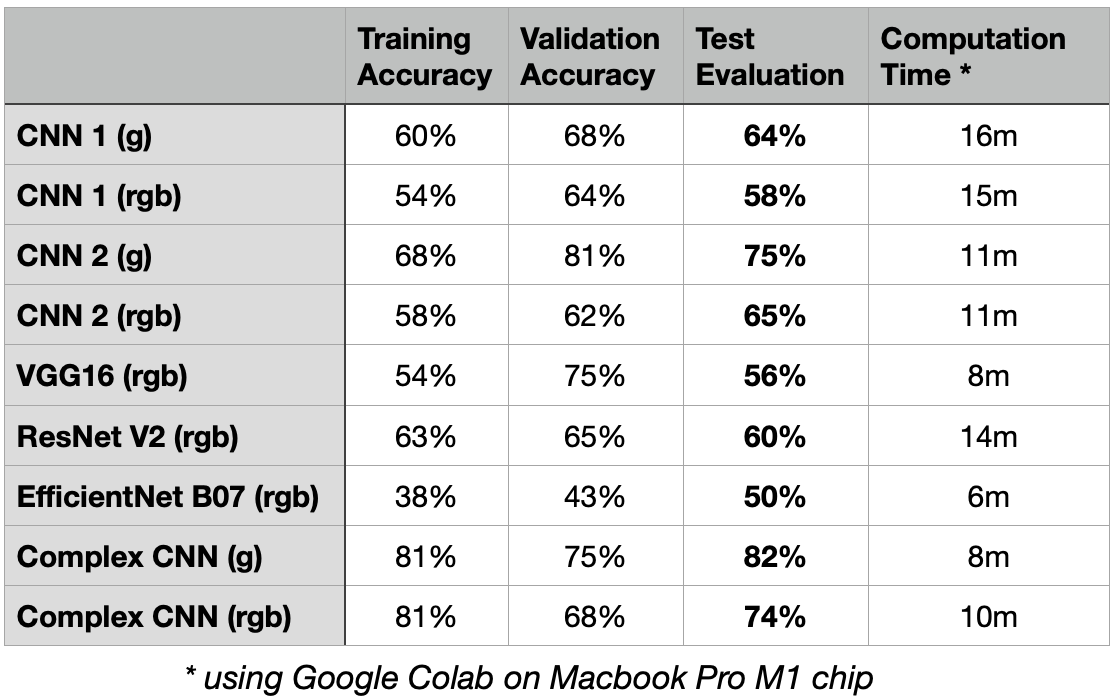
This deep learning project proposes the Complex Convolutional Neural Network (CNN) for the accurate detection of facial emotions. The dataset provided to train the models is composed of small size grayscale images of faces expressing four types of emotion: happy, sad, neutral or surprised. Using Transfer Learning did not prove beneficial in classifying the images of the given dataset. The performance of these pre-built architectures was lower than expected so building a more complex but flexible CNN model was the best approach to work with the specific dataset. The suggested model achieved high performance with 82% accuracy. However, it is subject to a number of limitations, including the lower accuracy in predicting certain classes, and when facial occlusion is present. Its computation efficiency is also linked to the volume and size of images to be processed.
Model Comparison
Below is a diagram explaining our workflow. We shall build different 6 models, train each model on the training dataset, monitor the performance of the model on the validation dataset and evaluate the model on the test dataset using the metric ‘accuracy’.
Recommendations
It is recommended that stakeholders consider the limitations and challenges in building an improved and robust predictive model, as well as use a larger and more diverse training dataset, explore data augmentation techniques to improve the model’s accuracy and evaluate the trade off of developing a more complex but more computationally expensive model.
Further Analysis
Further analysis to improve the model’s performance can be considered:
-
One possibility to train the Complex CNN on a larger dataset is to use datasets available to the public. If the dataset is in color mode, an additional data preprocessing step to convert the images from 3-color channels to a single color channel would be necessary.
-
Another possibility is to explore generating new images from existing ones using Generative Adversarial Networks (GANs) such as NVIDIA’s StyleGAN2 or Google’s Rapid and Accurate Image Super-Resolution (RAISR). However labelling the new images generated would incur additional costs.
Presentation
